I have built TQMemory as a high-performance, in-memory cache that can be used as a drop-in replacement for Memcached. It uses the same CLI flags, speaks the same protocol, and under some conditions it exceeds Memcached performance. When used as a Go package, it circumvents network, and can handle over 2.5 million GET requests per second (about 9x faster than Memcached over sockets).
See: https://github.com/mevdschee/tqmemory
What is TQMemory?
TQMemory is implemented in Go, and can be used as both as an embedded library and as a standalone server. It speaks the Memcached protocol (both text and binary), meaning that in server mode it works out-of-the-box with existing clients.
Performance
TQMemory is optimized for write-heavy workloads with larger values, such as SQL query results. Benchmarks were run with Unix sockets, 10 clients, and 10KB values:
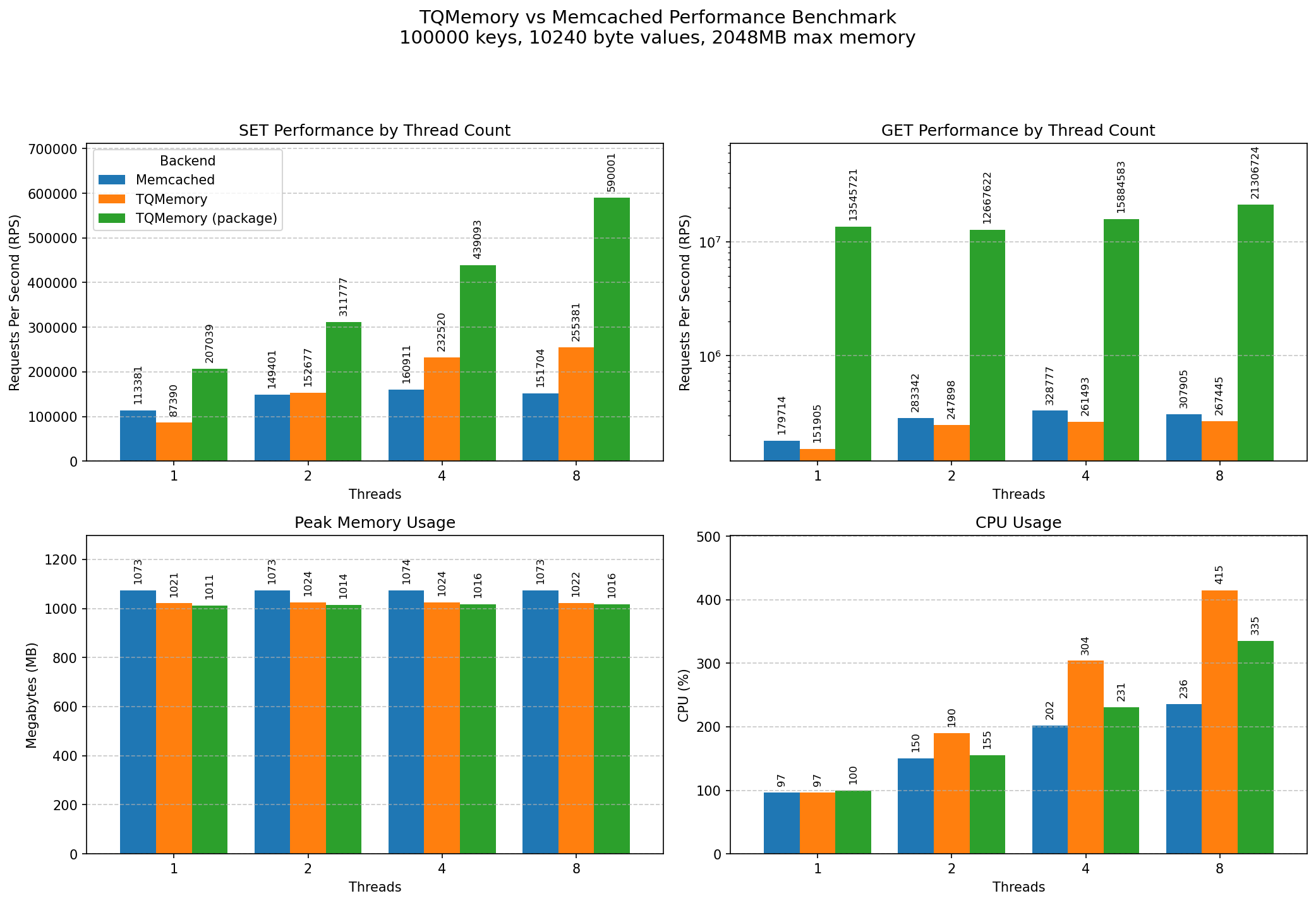
With 4 threads (and over sockets), TQMemory achieves 225K SET and 261K GET requests per second, compared to Memcached’s 149K SET and 281K GET. This means SET operations are about 51% faster than Memcached, while GET operations are roughly 7% slower.
I measured that about 80% of the overhead of TQMemory GET was due to network I/O. That’s why when you embed TQMemory as a package in your Go application, it is significantly faster. With 4 threads, the embedded package achieves 403K SET and 2.6M GET requests per second. In certain niche use cases, such high performance can be a game-changer.
How it Works
TQMemory uses a sharded, lock-free worker-based architecture:
- Sharded Cache: Keys are distributed across workers via FNV-1a hash
- Lock-Free Workers: Each shard has a dedicated goroutine handling all operations via a channel
- No Locks: Single-threaded per shard means no RWMutex or lock contention
- LRU Eviction: When memory limit is reached, least recently used items are evicted
Each worker maintains its own map for O(1) lookups, a min-heap for TTL expiration, and a linked list for LRU ordering. This provides predictable latency and simple reasoning about concurrency.
Use Case: SQL Query Result Caching
The primary use case I have built TQMemory for is caching expensive database queries. When embedded as a Go package, you get near-instant cache hits:
import "github.com/mevdschee/tqmemory/pkg/tqmemory"
// Initialize: 4 shards, 512MB memory limit
cache := tqmemory.NewShardedCache(4, 512*1024*1024)
func GetProducts(db *sql.DB, categoryID int) ([]Product, error) {
key := fmt.Sprintf("products:cat:%d", categoryID)
// Cache hit: ~2.6M RPS capable
if data, _, err := cache.Get(key); err == nil {
var products []Product
json.Unmarshal(data, &products)
return products, nil
}
// Cache miss: query database
products, err := queryProductsFromDB(db, categoryID)
if err != nil {
return nil, err
}
// Cache for 5 minutes
data, _ := json.Marshal(products)
cache.Set(key, data, 0, 300)
return products, nil
}
Conclusion
TQMemory is a specialized tool for Go developers who want a faster Memcache using in-process caching. I cannot recommend it as a replacement for Memcached as a network service, as Memcached has slightly better read performance (GET is ~7% faster) and TQMemory is not battle tested, while Memcached is rock solid.
Disclaimer: I’ve built TQMemory as a learning project for high performance caching. While benchmarks are promising, test thoroughly before using it in production.
NB: You may want to check out “Otter: In-memory caching library” as it seems to be a very performant and highly optimized option for Go programmers that is actually used by large projects like Centrifugo and FrankenPHP.